
Communities & AI: you need to create data in order to use it!
Communities are the best way to generate knowledge at scale, full stop. Google seems to agree; they recently revealed a new $60 million annual licensing deal with Reddit for rights to use the site’s data. Why? Because communities constantly create data that can’t be generated any other way.
- One of the most common types of questions we receive is something like “will this RØDECaster work with [some device I’ve never heard of before]?”
- Of course, these compatibility questions have always been hard to answer. Part of my job involves answering them! But our community is much better at doing this than I am.
- Products that have this data available (like ours) benefit from platforms like Discord existing, and lesser known products don’t.
Google & Reddit’s deal demonstrates that in the future, it will be a lot easier for LLMs to find, analyse and use data, but data still has to be created in the first place. That’s what communities do!
How I learned to stop worrying and love the bot
A large portion of my role at RØDE involves social media management – answering all of our community’s questions on eight social platforms. It’s worthwhile for our brand, but it’s time intensive.
Recently, I realised I was in the perfect situation to take advantage of recent advances in AI technology. I had the perfect use case, access to the best models, and all the data I needed at my fingertips. I had actually written a lot of that data myself, answering questions online!
After a bit of research, I realised the best available tool for me to educate myself on is RAG – Retrieval Augmented Generation.
On weekends and evenings after work, I taught myself to use a slew of tools like Python, MySQL, FastAPI, BeautifulSoup, and StreamLit, and built a prototype for RØDE using this technique.
You can play around with it below! 👇
https://aidobot-proofofconcept-v1-urjg4vmmua-uw.a.run.app/
Disclamer #1: This was just a very buggy proof-of-concept prototype. Disclaimer #2: forgive the narcissistic branding, it was a personal project 😅
The issue with technology-centered design in the age of AI
After using the tool as a part of my social media management duties regularly, like many others using these tools professionally, I often found that using the AI’s writing was more trouble than it was worth. But it was helpful in a different way.
I just used it to ask myself this:
Where is that piece of information stored? Was that one in a blog post, FAQ, user guide, article, social post, or did I just write that in a YouTube comment as a reply to someone?
I didn’t really care about the AI component of the tool, just the enormous database I had created.
I came to realise that despite how well versed in design theory and practices I am, I had committed an age old design sin: centering design around technologies rather than user needs.
My next prototype met my needs much better: a simple search tool.

In the end, my time learning web data scraping, SQL database management, and Python app development was well spent! I use this thing everyday. Eventually, I hope others at RØDE and folks in the community will be able to as well.
Could this system be used to analyse brand sentiment?
The tool above was designed to collate all of our social media comments into a vector database. This allows users to search the database using natural language and find results that match the meaning of their search terms.
Data scientists these days often use this exact same technology to perform sentiment analysis. It’s the same thing: vector databases can group phrases and comments with similar meanings across enormous datasets.
It wouldn’t be difficult to turn this to a tool that anyone at RØDE could use to:
- See what the worst feedback was about the Wireless GO II
- See what patterns of feedback we receive across all of our products
- Check if a certain bug has been experienced before
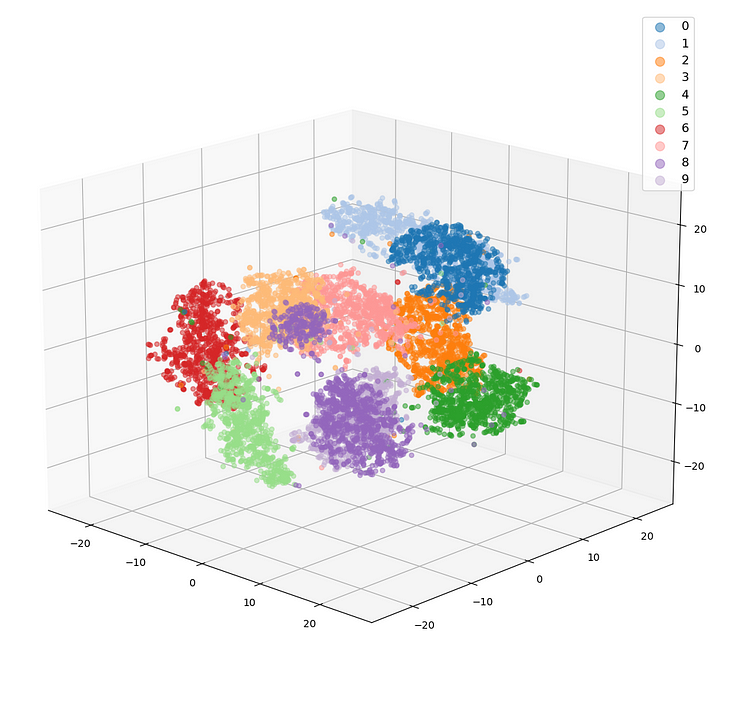 Source: A 3D diagram visualising the statistical analysis of text data in vector space. Certain clusters have been identified, as well as the closeness of clusters to one another.
Source: A 3D diagram visualising the statistical analysis of text data in vector space. Certain clusters have been identified, as well as the closeness of clusters to one another.
What did we learn from making this all work?
🏠 What I Learned Building the RØDE Community
Community structure:
💜 Community Strategy (Respect helpers, give them tools)
Community content strategy:
🎓 Community Content Strategy (Learn from audience misconceptions)
Using community data:
😎 Using Community Knowledge (Yep, another guy making chatbots)
Creating custom solutions:
🗺️ Creating a Meaningful Community UX (with Discord)
Service design:
🪄 Service Design (Brands compete on user experiences)
Proving it:
📈 Proving It (Result- chart line go up!)
Misc.
🌐 Why Discord? ❔ Further questions for discussion 📜 Footnotes 👋 Meet the team- one other guy