
What’s RAG?
RAG has become quite common in recent months as a way to use Large Language Models (LLMs) to provide information and answers without hallucination. Here’s a simplified explanation of how it works:
-
The user provides a query, which may be poorly phrased or spelled, for example,
“Can I use USB-NT plus with my apple phone?”
-
A retrieval system interprets the deeper meaning of this query, and matches it to the meanings of information stored in a vector database. The retrieval system finds the most relevant content to match this query.
Snippet from NT-USB User guide: If you are using an iPhone with a Lightning port, you will need to use a Lightning Accessory Cable like the SC19 to connect to the NT-USB+.
Note that the key phrases in that snippet don’t actually match the ones in the query! The matches from vector databases are based on semantic meaning.
-
Then, the system just queries an LLM, the same way that you might ask ChatGPT something. The only difference is that it also includes the context (e.g. that snippet from the user guide) in the query, as well as your question.
The LLM is receiving the user query and context which answers the question at the same time, so it is much more effective at returning with the correct answer. My early testing using this technology revealed as much!
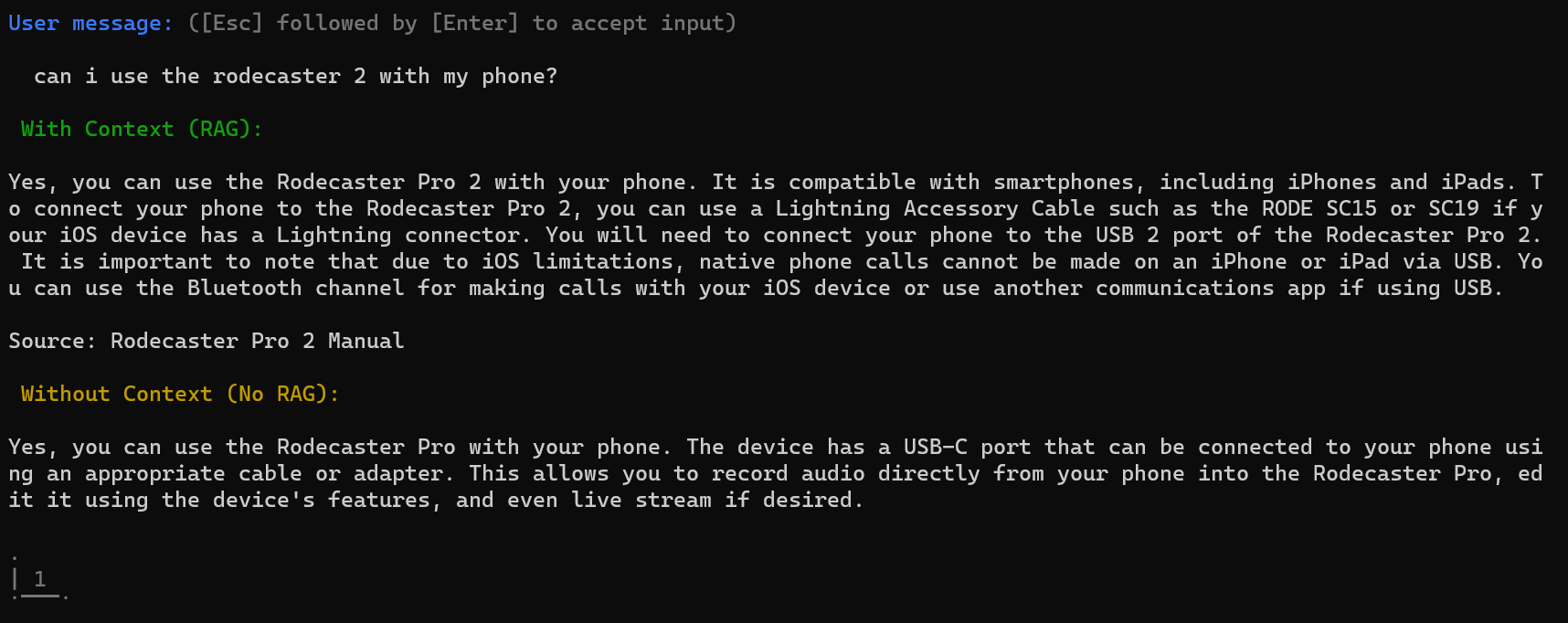
The first answer, using this RAG system, wasn’t perfect, but was almost usable. The second answer (just asking the LLM directly without context) was gibberish. Note how the RAG system is also able to return a source for this knowledge, alongside the answer. This is helpful not only to allow users to trace a piece of information and verify it, but also to give credit to the creators of that knowledge!
What is a vector database?
When you search a traditional database, the terms you use need to be an exact match to the results you’re looking for. But what if your question is messy, like “How do I make my voice sound better on streams?”
That’s where vector databases come in:
-
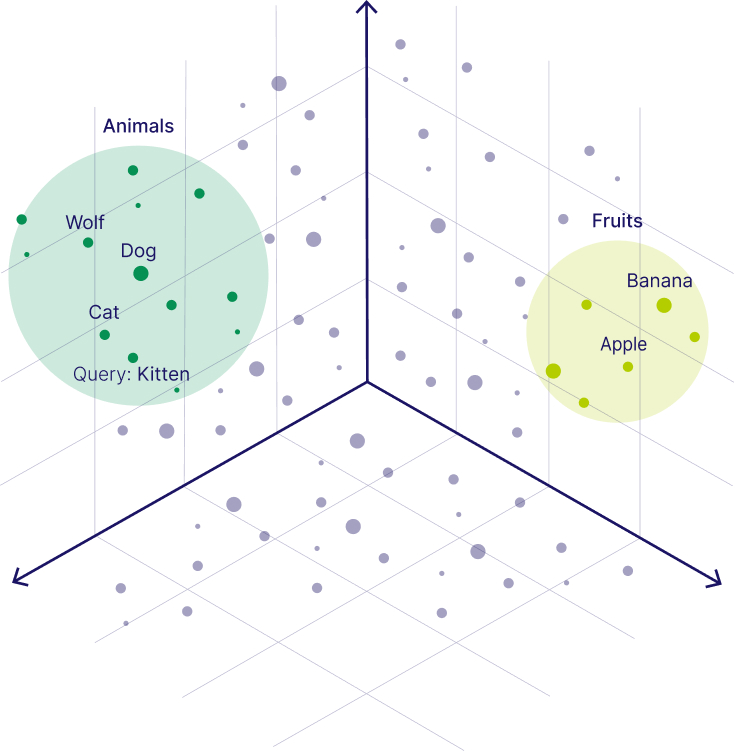
Each piece of info (article, guide, support transcript) gets translated into “vectors.” This is like a numerical fingerprint of its meaning, not just the exact words. Since they’re numbers, you could imagine them mapped into 3D space like in the diagram on the right.
-
Your question gets ‘translated’ into vectors too.
How is this translation done? It’s done with an ‘embeddings model’, which is a complicated AI model with a lot of similarities to an LLM.
-
The database finds the closest vectors, meaning the content most relevant to what you asked, even if the wording is totally different.
What did we learn from making this all work?
🏠 What I Learned Building the RØDE Community
Community structure:
💜 Community Strategy (Respect helpers, give them tools)
Community content strategy:
🎓 Community Content Strategy (Learn from audience misconceptions)
Using community data:
😎 Using Community Knowledge (Yep, another guy making chatbots)
Creating custom solutions:
🗺️ Creating a Meaningful Community UX (with Discord)
Service design:
🪄 Service Design (Brands compete on user experiences)
Proving it:
📈 Proving It (Result- chart line go up!)
Misc.
🌐 Why Discord? ❔ Further questions for discussion 📜 Footnotes 👋 Meet the team- one other guy